How To Identify The Duplicate Records Present In a Table In SQL Server
posted by Unknown @ 5:50 AM
0 Comments
![]()
posted by Unknown @ 5:50 AM
0 Comments
![]()



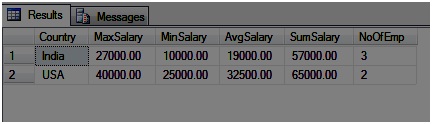

Labels: Aggregate functions in SQL, basics in sql, group by in sql, having in sql, SQL Basics, SQL Server Group by, SQL Server having, WHERE clause in SQL, where in sql
posted by Unknown @ 11:46 AM
0 Comments
![]()


Labels: basics in sql, case in sql server, Case Statement in SQL Server, if else in sql, SQL Basics, switch case in sql, when clause in sql, when Statement in SQL Server, WHERE clause in SQL, where in sql
posted by Unknown @ 11:37 AM
0 Comments
![]()


Labels: basics in sql, how to write sql query, not in sql, not operator in sql, regular expressions in sql, SQL Basics, WHERE clause in SQL, where in sql
posted by Unknown @ 11:32 AM
0 Comments
![]()


Labels: like operator in sql, regular expressions in sql, SQL Basics, usage of like, WHERE clause in SQL, where in sql
posted by Unknown @ 11:29 AM
0 Comments
![]()



Labels: Between operator in SQL, difference between IN and between in SQL Server, IN operator in SQL, SQL Basics, WHERE clause in SQL, where in sql
posted by Unknown @ 11:23 AM
0 Comments
![]()
|
Attributes/ Columns
|
|
EmployeeID
|
|
EmployeeName
|
|
DepartmentID
|
|
City
|
|
Country
|






Labels: how to write select query, order by in sql, SELECT, SELECT in SQL, select query in sql, SQL Basics, where in sql
posted by Unknown @ 11:16 AM
0 Comments
![]()




Labels: dbms relationships, differences between different relationships, relationships in database, Relationships in database management system, SQL Basics
posted by Unknown @ 11:06 AM
0 Comments
![]()
Labels: advantages of database, database over file system, difference between File System and Database, features of database, file system vs database, SQL Basics
posted by Unknown @ 10:39 AM
0 Comments
![]()

Subscribe to
Comments [Atom]